

 |
|

23.08.2022, 01:08
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|

AMD рассказала о серверных ускорителях вычислений Instinct MI200 из нескольких кристаллов на CDNA 2
В рамках конференции Hot Chips 34 компания AMD поделилась деталями о серверных ускорителях вычислений серии Instinct MI200 на базе графических процессоров Aldebaran на архитектуре CDNA 2. Это первые графические решения AMD, в составе которых применяется компоновка из нескольких кристаллов (чиплетов), также известная как MCM-компоновка.

Источник изображений: AMD Одними из ключевых особенностей Instinct MI200 являются: - архитектура CDNA 2 с матричными ядрами второго поколения для ускорения вычислений FP64 и FP32. Они до четырёх раз увеличивают производительность операций FP64 по сравнению с предыдущим поколением серверных ускорителей AMD;
- передовая технология упаковки 2.5D Elevated Fanout Bridge (EFB), позволяющая до 1,8 раза увеличить количество ядер и до 2,7 раза повысить пропускную способность памяти по сравнению с предыдущим поколением серверных GPU AMD, а также обеспечить пиковую пропускную способности памяти в 3,2 Тбайт/c;
- третье поколение шины AMD Infinity Fabric; поддержка до 8 линий Infinity Fabric, которые обеспечивают связь между несколькими самими AMD Instinct MI200, а также процессорами AMD EPYC, в том числе третьего поколения, что обеспечивает системе унифицированную память CPU/GPU и повышает максимальную пропускную способность.
В составе ускорителей AMD Instinct MI200 используется графический процессор с двумя кристаллами (чиплетами) — основным и второстепенным. Каждый кристалл содержит по 8 шейдерных движков, в каждом из которых находятся по 14 вычислительных блоков (Compute Units, CU) для операций FP64, FP32, а также матричные движки второго поколения для операций FP16 и BF16.
Таким образом на каждый кристалл приходятся по 112 вычислительных блоков или 7168 потоковых процессоров, а на весь GPU в целом — 224 CU или 14 336 потоковых процессоров. GPU производится с использованием 6-нм техпроцесса TSMC. В общей сложности в составе графического процессора присутствуют 58 млрд транзисторов.
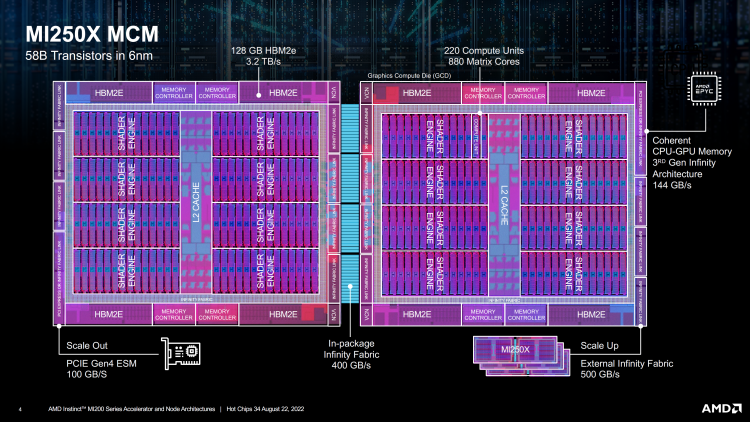
Блок-схема AMD Instinct MI200 GPU В составе графического процессора Aldebaran применяется скоростная шина xGMI. В составе каждого чиплета имеется движок VCN 2.6 и основной IO-контроллер, по четыре 1024-битных контроллера памяти HBM2e. На каждый чиплет также приходится по 8 Мбайт кеш-памяти L2, физически разделённой на 32 блока и по 64 Гбайт памяти HBM2e с пропускной способностью на уровне 1,6 Тбайт/с. Совокупный объём памяти HBM2e на GPU может достигать 128 Гбайт, а её пропускная способность составлять 3,2 Тбайт/с. Это на 1,2 Тбайт/с выше, чем у NVIDIA A100, оснащённой 80 Гбайт памяти HBM2e.
AMD Instinct MI200
 
AMD Aldebaran поддерживают 8 каналов Infinity Fabric. Один из них может использоваться для соединения CPU и GPU (по PCI Express). Оно рассчитано на согласованную передачу данных со скоростью 144 Гбайт/с. Показатель можно масштабировать до 500 Гбайт/с используя внешний канал Infinity Fabric с четырьмя подключёнными ускорителями AMD Instinct MI200 или с помощью PCIe 4.0 ESM AIC для пропускной способности на уровне 100 Гбайт/с.

Метрика производительности AMD Instinct MI200 AMD заявляет, что в зависимости от той или иной задачи Aldebaran может быть до трёх раз производительнее по сравнению с NVIDIA A100.
Ускорители вычислений AMD Instinct MI200 на архитектуре CNDA 2 уже используются в составе суперкомпьютера Frontier эксафлопсного уровня, возглавляющего рейтинг самых производительных суперкомпьютеров мира TOP500. Он обеспечивает производительность на уровне 1,1 эксафлопс.
AMD также сообщила о планах по выпуску нового поколения ускорителей вычислений Instinct MI300. В них тоже будет использоваться чиплетная компоновка, но это уже будут APU — на одной подложке будут сочетаться кристаллы CPU и GPU. Для Instinct MI300 заявляется использование архитектур CDNA 3 GPU и Zen 4 и до 5 раз более высокая производительность в ИИ-задачах по сравнению с архитектурой CDNA 2.
Источник: https://3dnews.ru/1072676/publikatsiya-1072676 |

|
|
23.08.2022, 01:10
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
Китайский ускоритель Birentech BR100 готов бросить вызов NVIDIA A100
Как известно, Китай первым в мире успешно ввёл в эксплуатацию суперкомпьютеры экзафлопсного класса, но современная HPC-система практически немыслима без ускорителей. Однако и здесь китайские разработчики подготовили прорыв: на конференции Hot Chips 34 компания Birentech рассказала о чипе BR100, решении, которое может бросить вызов как AMD, так и NVIDIA.
Новинка базируется на архитектуре собственной разработки под кодовым названием Bi Liren. Это первый китайский ускоритель общего назначения, использующий чиплетную компоновку и поддерживающий PCI Express 5.0/CXL. Новые ускорители будут сопровождаться полноценной программной поддержкой, начиная с драйверов и библиотек и заканчивая популярными фреймворками, такими, как TensorFlow и PyTorch.

Источник: WCCFTech Сложность BR100 внушает уважение: новый чип состоит из 77 млрд транзисторов, скомпонованных воедино с использованием 7-нм техпроцесса и технологии TSMC 2.5D CoWoS. Площадь чипа составляет 1074 мм2, правда, не очень понятно, идёт ли речь исключительно о кристалле, т.н. «вычислительном тайле», или о сборке в целом, поскольку в состав BR100 входит 64 Гбайт памяти HBM2e.

Источник: WCCFTech Среди особенностей можно отметить наличие быстрого кеша объёмом 300 Мбайт (256 Мбайт L2) — для сравнения, у NVIDIA A100 он составляет всего 40 Мбайт, и даже у новейшего H100 он увеличен лишь до 50 Мбайт. Что касается ПСП, то она составляет 1,64 Тбайт/с.
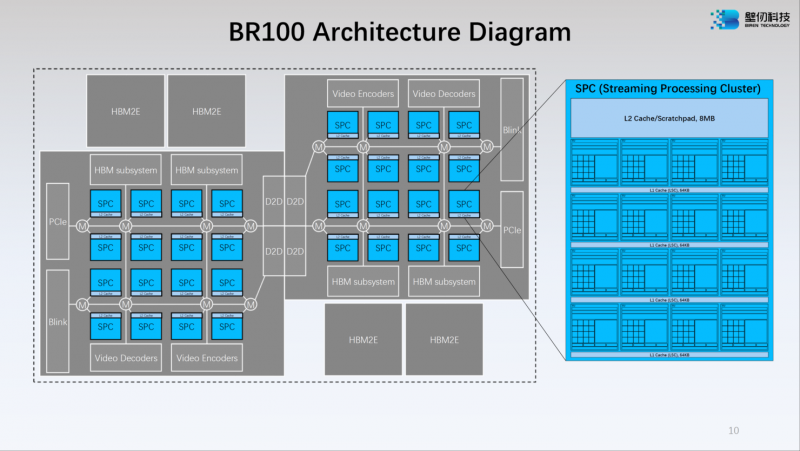
Источник: WCCFTech Модульная компоновка BR100 включает в себя два вычислительных тайла и четыре сборки HBM2e. Между собой кристаллы соединены интерконнектом с пропускной способностью 896 Гбайт/с, а для дальнейшего масштабирования в составе нового ускорителя предусмотрен фирменный интерконнект BLink (8 линий) с производительностью 2,3 Тбайт/с.

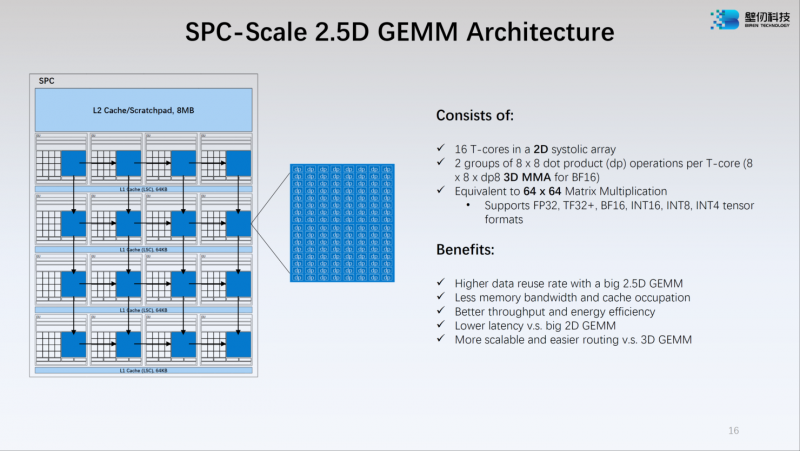
Источник: WCCFTech Каждый из двух кристаллов несёт в себе по 16 потоковых вычислительных кластеров (SPC), а каждый такой кластер, в свою очередь, содержит 16 исполнительных блоков (EU). Каждый блок EU содержит 16 потоковых ядер V-Core и одно тензорное ядро T-Core, так что всего в составе BR100 имеется 8192 классических ядра и 512 тензорных. Каждый SPC имеет свой кеш L2 объёмом 8 Мбайт, суммарно 256 Мбайт на всю сборку BR100.
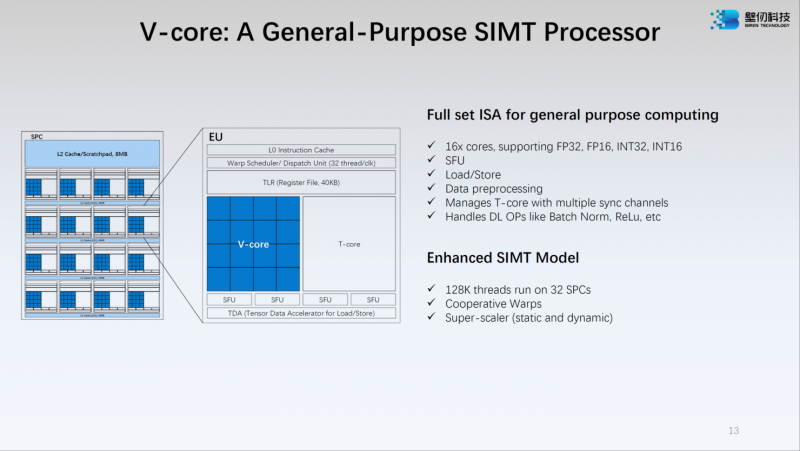
Источник: WCCFTech Ядро V-Core имеет архитектуру SIMT (Single Instructions, Multiple Thread) и поддерживает вычисления в форматах INT16/32, FP16 и FP32. Тензорные ядра T-Core предназначены для выполнения операций типа MMA, свёртки и прочих, характерных для современных задач машинного обучения. Предельное количество потоков у BR100 в суперскалярном режиме — 128 тысяч.
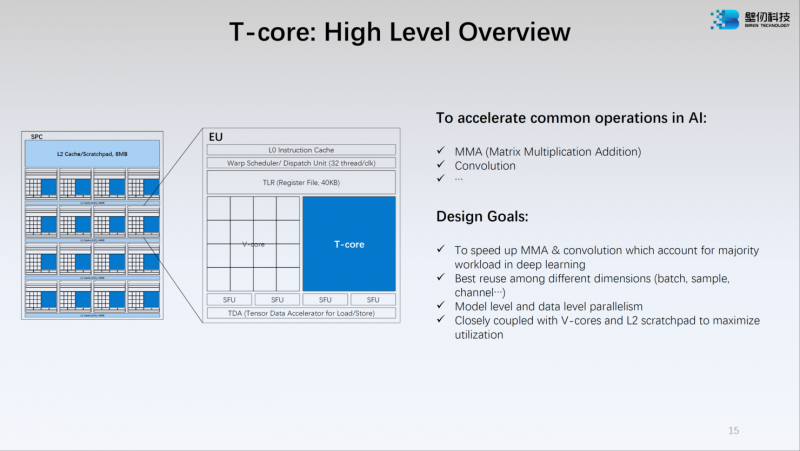
Источник: WCCFTech Компания-разработчик приводит некоторые цифры производительности для BR100: это 256 Тфлопс в режиме FP32, вдвое больше в режиме TF32+, 1024 Тфлопс в формате BF16 и целых 2048 Топс в режиме INT8. Это серьёзная заявка: с такими показателями BR100 должен опережать NVIDIA A100. Заявлено превосходство от 2,5х до 2,8х в зависимости от задачи и сценария.
Источник: WCCFTech Любопытно, что BR100 несильно уступает NVIDIA H100 по количеству транзисторов (77 против 80 млрд), но, естественно, использование более грубого 7-нм техпроцесса против N4 у последней разработки NVIDIA означает и большее тепловыделение. Этот параметр у BR100 составляет 550 Вт в то время, как PCIe-вариант H100 укладывается в стандартные 350 Вт.

Источник: WCCFTech Это не единственная новинка: в арсенале Birentech заявлен и менее мощный чип BR104. Он вдвое медленнее старшей модели по всем показателям и несёт 32 Гбайт памяти против 64, но в отличие от BR100, использует монолитный, а не чиплетный дизайн. На его основе будут выпущены ускорители в формате PCIe с TDP в районе 300 Вт, тогда как старшая версия будет доступна только в виде OAM-модуля.
Источник https://servernews.ru/1072678 |
|
|
|
24.08.2022, 20:47
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
72-ядерный процессор с 68 линиями PCIe 5.0. Nvidia рассказала подробности о CPU Grace
Есть ещё двойной Grace CPU Superchip
Компания Nvidia наконец-то полноценно рассказала о своём процессоре Grace, который первоначально показала ещё в апреле 2021 года.

Итак, Grace CPU представляет собой 72-ядерный процессор на основе архитектуры Arm v9.0. Он содержит 117 МБ кеш-памяти L3 и 68 линий PCIe 5.0, а производиться будет на мощностях TSMC по техпроцессу 4 нм.
Процессор предназначен для ЦОД, и стоит напомнить, что у Nvidia будет Grace CPU Superchip — фактически два объединённых процессора Grace.

Grace, кроме прочего, первый в мире процессор с поддержкой памяти ECC LPDDR5x с общей пропускной способностью в 1 ТБ/с. Также можно выделить интерфейс C2C NVLINK с пропускной способностью в 900 ГБ/с и вдвое большую производительность на ватт в сравнении с ведущими современными CPU.
Что касается производительности, в Specrate_int_base Grace набирает 370 баллов, а Grace CPU Superchip показывает результат в 740 баллов. Для сравнения: пара Epyc 7763 (128 ядер суммарно) набирает 861 балл. При этом Grace CPU Superchip потребляет около 500 Вт, а два упомянутых процессора Epyc требуют около 560 Вт.
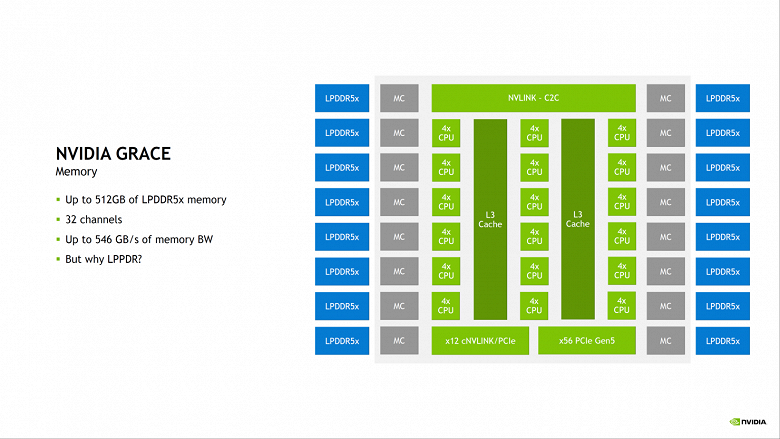
Также стоит отметить, что Grace — узкоспециализированный CPU для задач обучения моделей NLP. То есть напрямую сравнивать его с Epyc или Xeon не очень корректно.
Источник https://www.ixbt.com/news/2022/08/24/72-68-pcie-5-0-nvidia-cpu-grace.html |
|
|
|
24.08.2022, 20:48
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
AMD готовит очень быстрые и ещё более быстрые процессоры, и это в рамках одного поколения. Появились тесты Ryzen 7000X3D
Ожидаются модели Ryzen 7 7800X3D и Ryzen 9 7950X3D
Компания AMD ранее уже говорила, что позже выпустит CPU нового поколения с технологией V-Cache. И сегодня у нас есть первые слухи касательно таких процессоров.

Согласно данным источника, объём микросхемы V-Cache останется равным 64 МБ, как у Ryzen 7 5800X3D. При этом это будет уже второе поколение технологии, так что как минимум будет повышена пропускная способность. К тому же есть вероятность, что AMD может наделить старшие модели двумя такими микросхемами, то есть прибавить по 128 МБ кэш-памяти.
Если основные процессорные кристаллы Ryzen 7000 будут производиться по техпроцессу 5 нм, то кристаллы V-Cache будут выпускаться по нормам 6 либо 7 нм.

Самое интересное, что уже есть результаты тестирования. Правда, во-первых, неясно, в каких тестах, а во-вторых, экземпляр нового CPU опирался на степпинг A0, то есть это несерийный образец, который работал на частотах ниже финальных. Но даже в таком виде, как можно видеть, новинка ощутимо быстрее аналога без V-Cache и уж тем более решений текущего поколения. Более того, для всех протестированных CPU установлен одинаковый лимит мощности в 105 Вт. А старшие Ryzen 7000, как известно, должны иметь TDP в 170 Вт. То есть фактически в рамках одного поколения AMD выпустит очень быстрые CPU и ещё более быстрые.
AMD Zen 4 V-Cache Early Leak: Intel shouldn’t get greedy with Raptor Lake…
I have early Zen 4 V-Cache performance numbers…Intel Raptor Lake is on borrowed time… [SPONSOR: https://www.aliexpress.com/campaign/2022-sale/main-venue-US-8...
www.youtube.com
Источник говорит, что Ryzen 7000X3D запланированы на первое полугодие 2023 года. Ожидается, что дополнительную память получат две модели: Ryzen 7 7800X3D и Ryzen 9 7950X3D.
Источник https://www.ixbt.com/news/2022/08/24/amd-ryzen-7000x3d.html |
|
|
|
25.08.2022, 20:12
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
Intel говорит, что чипы будут иметь триллион транзисторов уже к концу десятилетия. Правда, такие решения есть уже сейчас
Глава Intel поделился видением будущего
Компания Intel ожидает, что уже к 2030 году на рынке будут присутствовать полупроводниковые чипы с триллионом транзисторов.

Об этом рассказал глава компании Пэт Гелсингер (Pat Gelsinger), выступая на конференции Hot Chips.
Сегодня в корпусе содержится около 100 миллиардов транзисторов, и мы ясно видим путь к триллиону транзисторов к концу десятилетия. С ленточными полевыми транзисторами у нас есть принципиально новая структура транзисторов, которую мы вот-вот начнем внедрять, и мы считаем, что транзисторный бюджет продолжит расти до конца десятилетия
Если заглянуть на 10 лет назад, то можно увидеть, что топовые GPU того времени содержали около 3-4 млрд транзисторов. Сейчас речь идёт уже о 50-80 млрд транзисторов.
Конечно, уже сейчас есть Cerebras WSE-2 с её 2,6 трлн транзисторов, но тут речь идёт об очень специфическом решении. Глава Intel же явно имел в виду более стандартные чипы.
Также он высказался касательно того, что Intel видит будущее в чиплетных технологиях, трёхмерной компоновке чипов и объединении всё большего числа различных компонентов в рамках одного полупроводникового чипа. Собственно, движение в этом направлении мы видим уже сейчас, а в следующем году нас ждут процессоры Meteor Lake, в которых эта концепция выйдет на новый уровень.
Источник https://www.ixbt.com/news/2022/08/2...tiletija-pravda-takie-reshenija-est-uzhe.html |
|
|
|
27.08.2022, 19:42
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
Процессор Qualcomm, голосовое управление, Android 11: это не смартфон, а новые очки дополненной реальности
Они предназначены для медиков, инженеров и сотрудников компаний
В компании Vuzix представил новую модель очков дополненной реальности Blade 2. Эта модель рассчитана на корпоративное применение. Её также позиционируют как систему для медиков, инженеров и других специалистов, которым нужная информация необходима буквально перед глазами.

Очки получили дисплей для правого глаза с разрешением 480 × 480 пикселей. Яркость превышает 2000 кд/м2, угол поля зрения составляет 20 градусов.

Внутри установлен четырёхъядерный процессор Qualcomm, модель его не уточняется. Есть также трёхосный гироскоп и акселерометр, стереодинамики, камера с автофокусом, два микрофона с шумоподавлением, порт USB 2.0 типа micro-USB и целых 40 ГБ постоянной памяти.
VUZIX 2022 BLADE 2
www.youtube.com
Очки работают под управлением ОС Android 11, на одной из дужек есть сенсорная панель управления. Vuzix Blade 2 сопрягаются с со смартфонами под управлением Android и iOS.
Как ожидается, новинка появится в продаже в сентябре по цене в 1300 долларов.
Источник https://www.ixbt.com/news/2022/08/27/qualcomm-android-11.html |
|
|
|
28.08.2022, 19:56
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
Samsung тестирует третье поколение процессоров Tensor. Pixel 8 на подходе?
Характеристики не указаны
Компания Google пока ещё не выпустила свою новую линейку смартфонов Pixel 7 на базе второй версии процессоров Google Tensor, а Samsung уже тестирует третью версию чипов. Как ожидается, эти процессоры появятся в Pixel 8 в следующем году.

На данный момент наверняка можно сказать не слишком многое. Инженерная версия чипа тестируется на плате для разработчиков с названием Cloudripper. Модельный номер — S5P9865. У первого Tensor он был S5P9845, а у второго — S5P9855.
Пока что неясно, на каком этапе разработки находятся новые чипы и чем они превосходят второе поколение. Ожидается, что новые данные появятся в ближайшие месяцы.
Ранее в сети показали прототипы Google Pixel 7 и Pixel 7 Pro. На изображении видно, как отличается задняя панель у разных версий.
Источник https://www.ixbt.com/news/2022/08/28/samsung-tensor-pixel-8.html |
|
|
|
28.08.2022, 19:58
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
NVIDIA поделилась подробностями об ускорителях H100 на базе
архитектуры Hopper
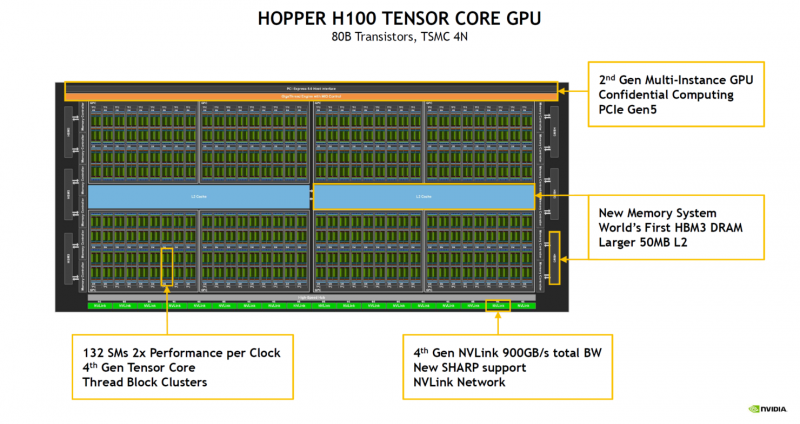
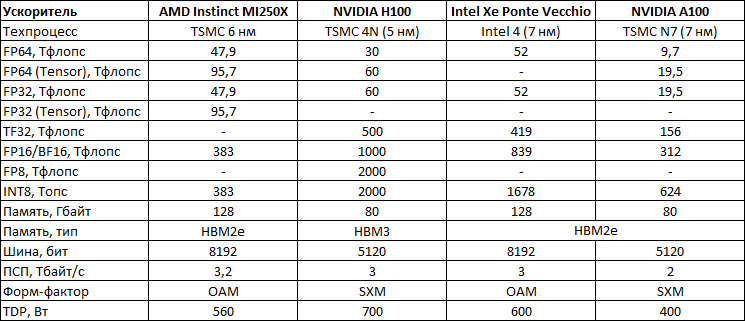
На конференции Hot Chips 34 NVIDIA поделилась новыми подробностями о грядущих ускорителях H100 на базе архитектуры Hopper. Чип GH100 содержит 80 млрд транзисторов и производится с использованием специально оптимизированного для нужд NVIDIA техпроцесса TSMC N4, созданного в содружестве с NVIDIA. Ускоритель первым в мире получит память HBM3.
В составе чипа есть сразу 144 потоковых мультипроцессоров (SM), что несколько больше, нежели в A100, где таких блоков физически 128. Активных блоков же всего 132, но NVIDIA заявляет о вдвое более высокой производительности новых SM при сравнении с прошлым поколением при равной частоте. Это относится как к модулям FP32, так и FP64 FMA. В дополнение появилась поддержка формата FP8, всё чаще встречающегося в сценариях машинного обучения, не требующих высокой точности вычислений.
Здесь и далее источник изображений: NVIDIA via ServeTheHome
В этом режиме NVIDIA поддержала оба наиболее распространённых формата FP8: E5M2 и E4M3, то есть представление числа в форме 5 или 4 бита экспоненту и 2 или 3 бита на мантиссу соответственно. Каждый тензорный блок FP8 обеспечивает перемножение двух матриц в формате FP8 с дальнейшим накоплением и преобразованием результата, но самое важное здесь то, что благодаря наличию нового блока Transformer Engine выбор наиболее подходящего варианта FP8 осуществляется автоматически. Если верить NVIDIA, усовершенствованная архитектура тензорных процессоров с поддержкой FP8 позволяет добиться точности, сопоставимой с FP16, но при вдвое более высокой производительности и вдвое меньшем расходе памяти.
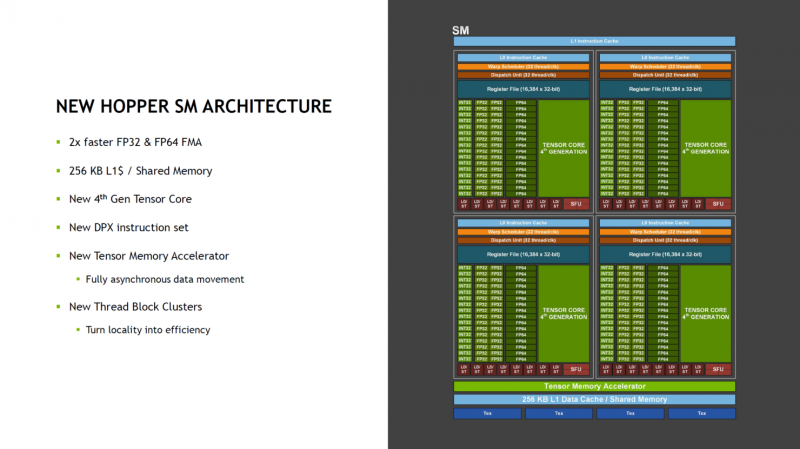 Всего каждом блоке SM имеется 128 модулей FP32, по 64 модуля INT32 и FP64 и по 4 тензорных ядра, а также тензорный ускоритель работы с памятью и общий L1-кеш объёмом 256 Кбайт. Объём L2-кеша составляет целых 50 Мбайт. В текущей реализации доступно 16896 CUDA-ядер из 18432 возможных и 528 тензорных ядер из 576. Вдвое быстрее, по словам NVIDIA, стали и новые модули тензорных вычислений, относящиеся уже к четвертому поколению. Внедрена поддержка нового набора инструкций DPX, появилась поддержка асинхронности при перемещении данных и т.д.
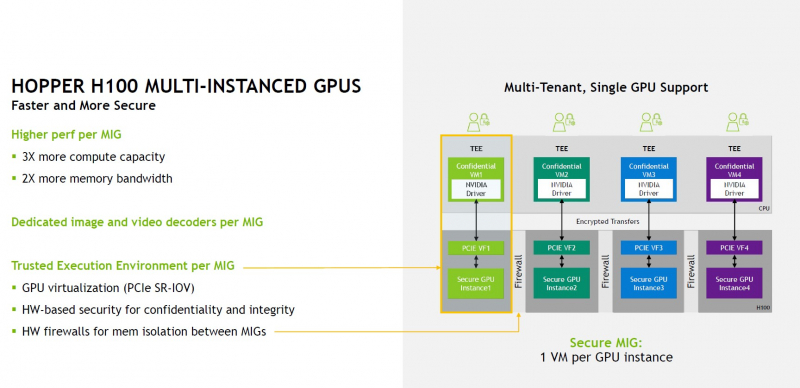 До второго поколения подросла технология MIG (Multi-instance GPU). Теперь на каждый такой виртуальный ускоритель стало приходиться в три раза больше вычислительных мощностей и в два раза — пропускной способности памяти. Последнее достигнуто благодаря применению HBM3. В данном варианте применены сборки HBM3 объёмом 16 Гбайт каждая (5120-бит шина). Пять сборок дают 80 Гбайт локальной памяти с ПСП 3 Тбайт/с. Посадочных мест для сборок шесть, но одно используется только для выравнивания высоты чипа
При этом виртуализация у GH100 полная, насколько это вообще возможно: обеспечена поддержка доверенных вычислений на аппаратном уровне, включая специализированные блоки брандмауэров, обеспечивающих изоляцию регионов памяти каждого vGPU, а также блоки проверки целостности и поддержки конфиденциальности данных. О поддержке нового поколения интерконнекта NVLink 4 мы рассказывали ранее — этот интерфейс даёт до 900 Гбайт/с для объединения нескольких чипов и ускорителей, но, главное, предоставляет гибкие возможности масштабирования.
Имеется у GH100 и ещё одно важное нововведение — модифицированная иерархия памяти. Так, интерконнект SM-to-SM позволяет каждым четырём SM общаться между собой напрямую, а не загружать излишними транзакциями общую шину. Это повышает эффективности при виртуализации и серьёзно экономит пропускную способность «главных трактов» ускорителя. Вкупе с поддержкой асинхронного исполнения и обмена данными это позволит снизить латентность, в некоторых случаях до семи раз.
Реализует ли NVIDIA потенциал GH100 полностью, на данный момент неясно, но это могло бы повысить и без того серьёзный потенциал новинки. Впрочем, такая мощь даром не даётся: даже в усечённой версии и даже несмотря на использование оптимизированного техпроцесса ускоритель на базе GH100 в формате SXM5 (плата PG520) будет иметь теплопакет 700 Вт.
Несомненно, GH100 —огромный шаг вперёд в сравнении с GA100, однако конкуренция предстоит серьёзная: так, новинке предстоит сразиться с ускорителями на базe Intel Ponte Vecchio, а в них обещается соотношение FP32/FP64 на уровне 1:1 против 2:1 у решения NVIDIA. Любопытный факт: единственный кластер GPC у нового чипа на 20% мощнее всего чипа GK110 Kepler, выпущенного всего 10 лет назад.
Источник https://servernews.ru/1073047 |
|
|
|
28.08.2022, 21:53
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
Qualcomm выпустит 4-нм чип Snapdragon 6 Gen 1 с поддержкой 5G и Wi-Fi 6E
В распоряжении сетевых источников оказались подробные характеристики мобильного процессора Snapdragon 6 Gen 1, который в скором времени анонсирует Qualcomm. Чип найдёт применение в смартфонах среднего уровня с поддержкой 5G.

Источник изображения: Qualcomm
Обнародованные данные, судя по представленному ниже слайду, утекли у самой компании Qualcomm. Новый процессор будет изготавливаться по 4-нм технологии. Он получит вычислительные ядра Kryo с тактовой частотой до 2,2 ГГц и графический ускоритель Adreno с поддержкой OpenCL 2.0 FP, Vulkan 1.1, OpenGL ES 3.2.
Интегрированный модем Snapdragon X62 5G обеспечит возможность работы в частотном диапазоне ниже 6 ГГц и в диапазоне миллиметровых волн. Скорость передачи данных в сторону абонента теоретически сможет достигать 2,9 Гбит/с.
Для платформы Snapdragon 6 Gen 1 предусмотрена поддержка беспроводной связи Wi-Fi 6E и Bluetooth 5.2, оперативной памяти LPDDR5-2750 максимальным объёмом 12 Гбайт, интерфейса USB 3.1, навигации GPS/BeiDou/ГЛОНАСС/Galileo/QZSS.
Разработчики смогут комплектовать устройства дисплеем формата до Full HD+ с частотой обновления до 120 Гц, камерами с разрешением до 48 млн пикселей или двойными камерами в конфигурации 25 + 16 млн пикселей. Более подробные характеристики изделия приведены ниже:

Источник изображения: Qualcomm / Evan Blass |
|
|
|
30.08.2022, 17:59
|
|
Постоянный
Регистрация: 03.09.2006
Сообщений: 872
С нами:
10360604
Репутация:
0
|
|
Все настольные Ryzen 7000 получили графическое ядро, но для игр оно не годится
В ходе минувшей презентации процессоров Ryzen 7000 глава компании AMD Лиза Су (Lisa Su) упустила одну важную деталь о новых чипах. Она не рассказала о том, что они оснащены встроенной графикой. Однако позже эта информация была подтверждена на официальном сайте производителя.

Источник изображений: AMD AMD указывает, что все четыре представленных процессора серии Ryzen 7000 имеют одинаковую встроенную графическую подсистему. В её составе лежат два вычислительных блока (Compute Units, CU) на архитектуре RDNA 2, которые содержат в общей сложности 64 потоковых процессора. Базовая частота встроенной графики Ryzen 7000 составляет 400 МГц, а максимальная — 2200 МГц.
Чипы Ryzen 7000 является первыми настольными процессорами AMD вне серии гибридных моделей с префиксом «G», которые получили встроенную графику. В рамках платформы Socket AM4 компания выпустила несколько серий гибридных APU, включая Renoir и Cezanne, оснащённых встроенной графикой. Однако графика в Ryzen 7000 заведомо слабее — небольшое графическое ядро размещено в IO-чиплете и в первую очередь ориентировано не на игровое, а на офисное применение.
По сторонним оценкам два вычислительных блока с 64 потоковыми процессорами могут обеспечить производительность на уровне 0,563 Тфлопс. Это примерно 1/3 производительности графики портативной консоли Steam Deck, у которой имеются 8 вычислительных блоков, работающих на частоте 1,6 ГГц.
К слову, аналогичная Ryzen 7000 графическая подсистема ожидается в составе процессоров AMD серии Mendocino. Эти мобильные чипы будут использоваться в доступных и маломощных ноутбуках на базе операционной системы ChromeOS.

Источник изображения: VideoCardz Старт продаж процессоров Ryzen 7000 запланирован на 27 сентября. Цены на новые чипы варьируются от $299 за младшую шестиядерную до $699 за флагманскую 16-ядерную модель.
Источник: https://3dnews.ru/1073224/publikatsiya-1073224 |
|
|
|
|
|
|
|
Здесь присутствуют: 1 (пользователей: 0 , гостей: 1)
|
|
|
|


































 Линейный вид
Линейный вид
